
跟学笔记:bilibili跟李沐学AI【论文精读】系列学习笔记1————读论文的方法论
1. 如何读一篇论文(方法论)
| 内容 | 第一遍 | 第二遍 | 第三遍 |
|---|---|---|---|
| title | yes | yes | |
| abs | yes | yes | |
| intro | related paper | yes | |
| method | graph | yes | yes |
| exp | graph | yes | yes |
| conclu | yes | yes |
第一遍,这篇论文是做什么,和我相不相关,结果和方法(图表)怎么样,适不适合自己(十几分钟)。
第二遍,从头到尾读一遍,不用过于注意细节,例如公式的证明;但是要清楚地看懂重要的图表,例如方法中的流程图、算法图,实验中的数据的含义(e.s, x、y轴坐标含义);圈出相关文献。
第三遍,在脑海中重复实现这个文章,提出什么问题,用什么方法怎么解决,实验如何做,后续工作可以怎么往前走。
2. 以AlexNet为例子,读一篇论文
第一遍
title:
ImageNet Classification with Deep Convolutional Neural Networks(2012)
author:
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
abstract:
很大很深的网络,在ImageNet任务上表现非常好
conclusion:
深度对网络表现很重要,减少一层降低2%;没有做pretrain(历史背景:之前人们主要关注无监督,有监督接近SVM,AlexNet影响后续很长一段时间大家关注于有监督学习,直到Bert出现);未来想训练video数据。
graph: 结果图片
第二遍
intro:
大数据集,ImageNet(15 million, 22000 categories);大模型,CNN虽然很好,但是容易过拟合;3、4章介绍模型结构和减少过拟合。
dataset:
raw RGB values(end-to-end,初始的文本和图片,不需要标记特征)
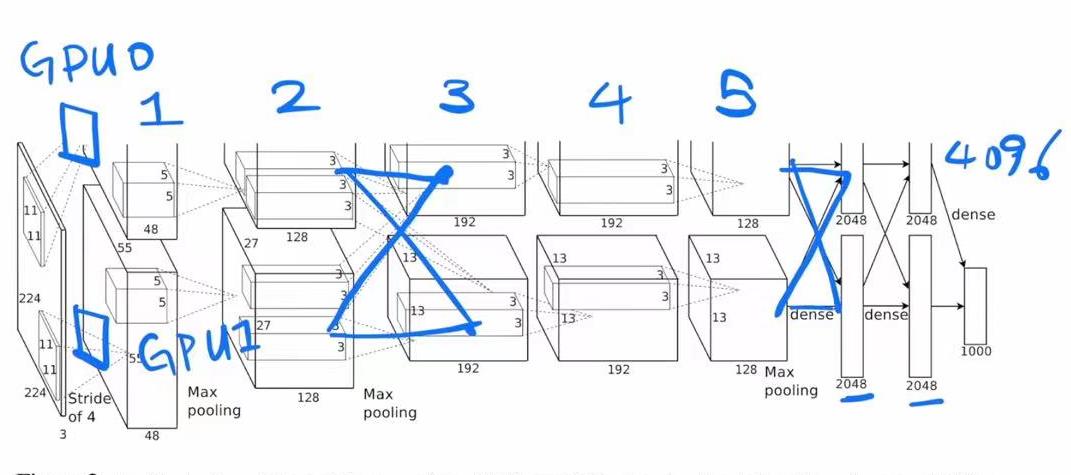
architecture:
- ?saturating nonlinearities饱和非线性函数,使用ReLU相比tanh训练快很多。
- 多GPU训练,系统工程细节(复现相关)。(历史背景:gpt,llm出现后又需要切割模型)
- Normalization正则化,避免过拟合。(历史背景:之后比这个有更好的正则方法)
- Pooling池化,做了些改动overlapping。
- overall, 随着网络加深,图片高宽变窄,通道数增加。(工程上有2个GPU,中间交叉通信最后连接。)知识压缩,变成机器可以理解的向量。
reducing overfitting:
- data augmentation数据增强,抠图,PCA颜色增强。
- dropout,相当于多个模型做融合(历史背景,之后证明dropout近似L2正则项,目前CNN不会使用特别大的全连接,dropout在全连接上比较有用)。如果没有dropout,过拟合严重,添加dropout收敛变慢。
details of learning:
- SGD: 历史背景,在AlexNet之后SGD(调参有一定难度)成为了主流,噪音对过拟合降低有好处。momentum,weight decay。
- Gaussian distribution, neuron biases, learning rate。
experiments:
结果如何?具体实现对于初学者不需要复现的情况下,不需要太关注。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 你找到了我的一个魂器!



